69. YOLO Image Object Detection Application#
69.1. Introduction#
YOLO is another commonly used object detection method different from R-CNN. In this challenge, you need to independently try to use relevant tools to complete the object detection application with YOLO.
69.2. Key Points#
Image object detection
YOLO real-time detection method
{note}
The first half of this challenge can be learned by following the methods of the experiment.
In 2015, the YOLO method was proposed. In 2018, YOLO had evolved into Version 3. The detection speed of YOLOv3 is extremely fast. According to the experimental results of the author in the related paper, YOLOv3 is more than 1000 times faster than R-CNN and 100 times faster than Fast R-CNN.
In the first half of this challenge, you will experience the object detection effect using the pre-trained YOLOv3 model. The challenge provides in advance the network of YOLOv3 built with PyTorch and a trimmed-down pre-trained model trained on the COCO dataset. The challenge directly clones the implementation code of YOLOv3.
!git clone "https://github.com/huhuhang/yolov3"
import sys
import warnings
warnings.filterwarnings('ignore')
sys.path.append("yolov3") # 添加路径
First, download the pre-trained YOLOv3 model on COCO.
import os
from yolov3.utils import download_trained_weights
download_trained_weights("yolov3_tiny_coco_01.h5") # 下载预训练模型
Then, we use the defined network and load the pre-trained
model
yolov3_tiny_coco_01.h5.
import torch
from yolov3.yolov3_tiny import Yolov3Tiny
model = Yolov3Tiny(num_classes=80) # COCO 数据集类别
model.load_state_dict(torch.load('yolov3_tiny_coco_01.h5'))
Next, use some predefined functional functions to read and process the test images. In fact, it is to read the images into numerical values, crop the shapes, and convert them into the PyTorch tensor type. Note that this pre-trained network only supports incoming image tensors of shape \([1, 3, n*32, n*32]\), that is, the length and width pixels must be multiples of 32.
from yolov3.utils import Image, image2torch
img_org = Image.open("yolov3/test.png").convert('RGB') # 读取图片
img_resized = img_org.resize((992, 480)) # 裁剪大小
img_torch = image2torch(img_resized) # 转换为张量
img_torch.shape
Immediately afterwards, you can perform object detection.
Here, call the
predict_img
method. This method can directly return the coordinate
parameters of the bounding boxes. Among them, you can set
the minimum confidence
conf_thresh
to filter out most of the unnecessary bounding boxes.
all_boxes = model.predict_img(img_torch, conf_thresh=0.3)[0]
len(all_boxes) # 边界框数量
Next, we can draw the bounding boxes on the image. Also, we need to define the class names of the COCO dataset.
# COCO 类别名称,顺序相关
class_names = ['person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
Finally, use the predefined
plot_img_detections
to draw the bounding boxes.
from yolov3.utils import plot_img_detections
plot_img_detections(img_resized, all_boxes,
figsize=(16, 8), class_names=class_names)
It should be intuitively felt that the speed of YOLOv3 is indeed much faster than using R-CNN for object detection in the previous experiments. For the above content, we used YOLOv3 built with PyTorch. There is a lot of code in this part, so it is not used in the challenge. If you are interested, you can read the source code.
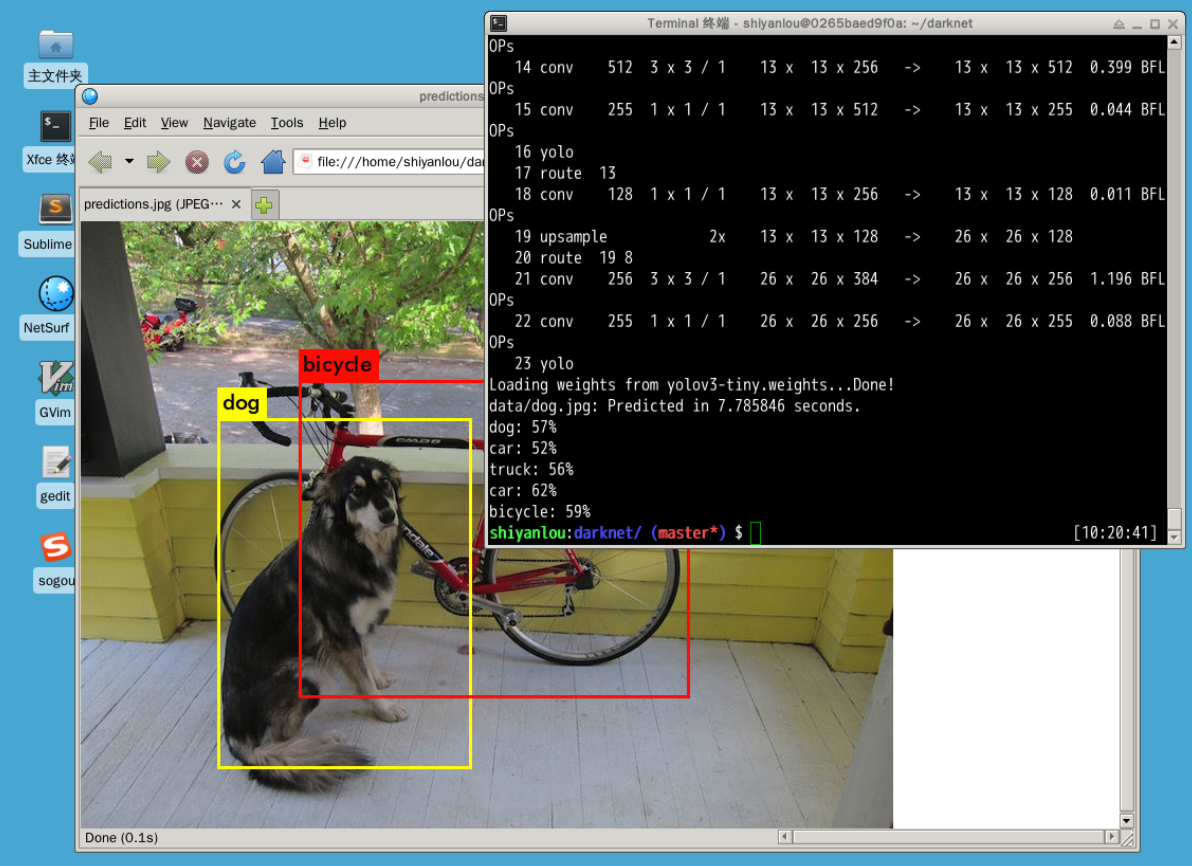
Actually, YOLOv3 itself also provides a tool called Darknet, which can be conveniently used to train and test object detection models built with YOLOv3. Darknet is developed in C language and has extremely high execution efficiency. The experience of using Darknet in the online Notebook is not good, so the next challenge is for you to familiarize yourself with the use of Darknet in the Linux desktop environment by yourself.
{exercise-start}
:label: chapter08_11_1
Open Challenge
Challenge: Please teach yourself how to use the Darknet tool and complete the object detection example process according to the getting-started materials provided by the developer.
Hint: Please read the Quick Start Guide provided by the developer and use the pre-trained model provided by it to perform object detection on any image. It is recommended that you use Linux to complete this challenge and make reasonable use of the search engine to troubleshoot problems encountered during use.
{exercise-end}
The download speed of the pre-trained model provided by the Darknet developer is relatively slow, and the challenge provides a mirror download address.
# Pre-trained model mirror download link
https://cdn.aibydoing.com/aibydoing/files/yolov3.weights
https://cdn.aibydoing.com/aibydoing/files/yolov3-tiny.weights
Expected output