
21. Decision Tree Model Parameter Optimization and Selection#
21.1. Introduction#
In the decision tree experiment, we implemented the complete decision tree classification process from scratch. Of course, at the end of the experiment, we also introduced how to build a decision tree model using scikit-learn. In fact, due to the pruning process in decision trees, there are a very large number of parameters involved. This challenge will guide you to optimize and select the parameters of machine learning models.
21.2. Key Points#
CART Decision Tree Classification
Grid Search Parameter Selection
It is estimated that you have already had such a question. Then when we build a machine learning model, how do we determine the appropriate parameters? Can we only use the default parameters? Or modify them blindly?
This challenge will guide you to find the answer to how to determine the appropriate parameters. In fact, sometimes we can estimate the general range of model parameters or optimization method parameters, or observe the changes in output or evaluation metrics through several simple manual modifications, so as to find the appropriate parameters.
However, sometimes it is unrealistic to determine parameters through several random attempts. For example, when several parameters involved in the decision tree modeling process, such as the maximum depth and the maximum number of leaf nodes, interact with each other, it becomes an extremely troublesome permutation and combination.
Next, we will introduce two commonly used hyperparameter selection methods: grid search and random search.
21.3. Grid Search#
Grid search, simply put, is to pre-determine a finite number of candidate values for each parameter in advance, and then pass in these parameters through permutation and combination. Finally, the method of K-fold cross-validation is used to determine the parameters with the best performance.
First, let’s talk about what K-fold cross-validation is. K-fold cross-validation is a common method in cross-validation. It evenly divides the dataset into K subsets, and successively uses K-1 of these subsets as the training set, while the remaining 1 subset is used as the test set. During the process of K-fold cross-validation, each subset will be validated once.
The following is an illustration to explain the process of K-fold cross-validation:
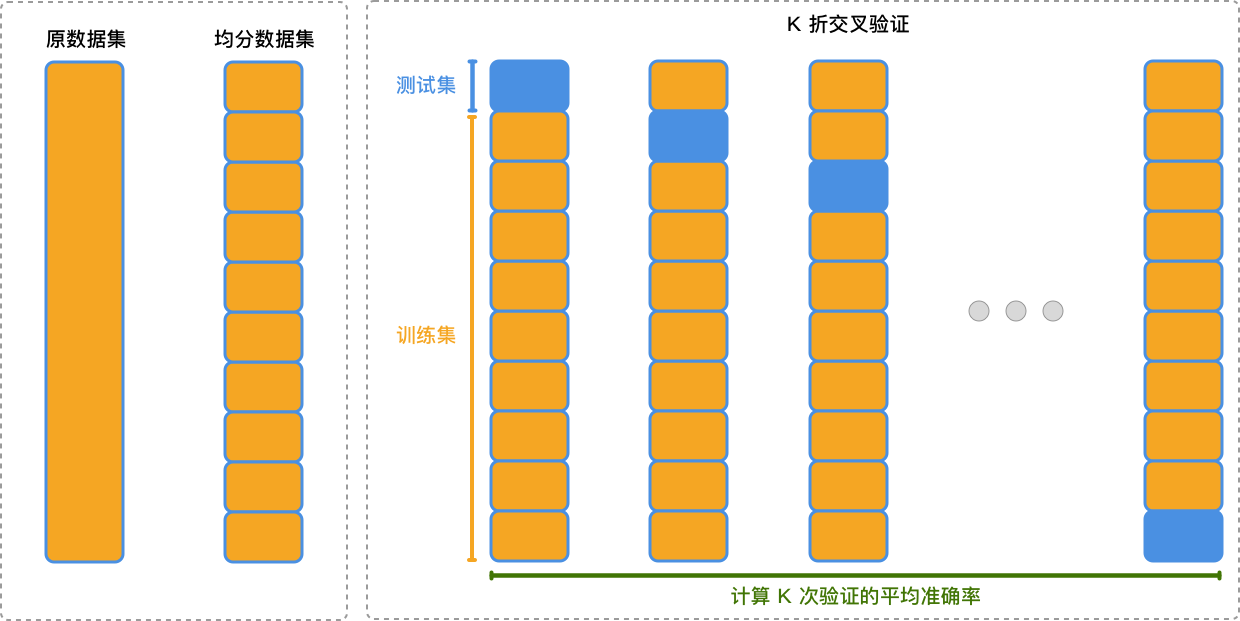
As shown in the figure above, the steps of using K-fold cross-validation are as follows:
-
First, evenly divide the dataset into K subsets.
-
Successively select K-1 of these subsets as the training set, and use the remaining 1 subset as the test set for experiments.
-
Calculate the average of the results of each validation as the final result.
Compared with manually dividing the dataset, K-fold cross-validation gives each piece of data an equal chance to be used for training and validation, which can improve the generalization ability of the model to a certain extent. There will be more introductions about cross-validation later. For this challenge, it can be completed only by specifying parameters.
Back to the definition of grid search. For example, a model has parameters A and B. We specify that parameter A has 3 parameters such as \(P1\), \(P2\), \(P3\), and parameter B has 3 parameters such as \(P4\), \(P5\), \(P6\). Then, there are 9 different cases through permutation and combination. Thus, we can traverse to test the performance of the model under different parameter combinations and obtain the best result.

Next, we first build a decision tree classification model. Here, we use the digits dataset provided by scikit-learn, which has been introduced before. Of course, you can use your own dataset for practice later.
from sklearn.datasets import load_digits
digits = load_digits()
digits.data.shape, digits.target.shape
((1797, 64), (1797,))
Next, use the decision tree algorithm provided by scikit-learn to implement classification.
Exercise 21.1
Challenge: Build a CART decision tree to complete classification and obtain the average classification accuracy of the 5-fold cross-validation results.
Requirement: Use the default parameters provided by
other methods except setting
random_state
=
42.
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
## 代码开始 ### (≈3 行代码)
model = None
## 代码结束 ###
Solution to Exercise 21.1
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
### Code starts ### (≈3 lines of code)
model = DecisionTreeClassifier(random_state=42)
cvs = cross_val_score(model, digits.data, digits.target, cv=5)
np.mean(cvs)
### Code ends ###
Expected output
≈ 0.7903
Next, we are going to use the grid search method to tune the
parameters commonly used in decision tree classification.
From the above grid search example, we know that grid search
can be achieved through loops, but here we directly use the
GridSearchCV
method provided by scikit-learn to implement it.
Exercise 21.2
Challenge: Learn and use
GridSearchCV
to complete grid search parameter selection and finally
obtain the best result of 5-fold cross-validation.
Regulation: For the CART decision tree, search candidate
parameters
[2,
10,
20]
for
min_samples_split, and search candidate parameters
[1,
5,
10]
for
min_samples_leaf. For other parameters not specifically specified, use
the default values.
Read and learn by yourself: GridSearchCV official documentation | GridSearchCV official example
from sklearn.model_selection import GridSearchCV
## 代码开始 ### (≈3 行代码)
gs_model = None
## 代码结束 ###
Solution to Exercise 21.2
from sklearn.model_selection import GridSearchCV
### Code start ### (≈3 lines of code)
# Dictionary of parameters to be searched
tuned_parameters = {"min_samples_split": [2, 10, 20],
"min_samples_leaf": [1, 5, 10]}
# Grid search model
gs_model = GridSearchCV(model, tuned_parameters, cv=5)
gs_model.fit(digits.data, digits.target)
### Code end ###
Run the test
gs_model.best_score_ # 输出网格搜索交叉验证最佳结果
Expected output
≈ 0.790
In fact, you can also output relevant information through some attributes of the model. For example, view the best parameters after grid search as follows.
gs_model.best_estimator_ # 查看网格搜索最佳参数
21.4. Random Search#
Grid search is intuitive and convenient, but the biggest problem is that as the number of candidate parameters increases, the time required for the search increases rapidly. Therefore, sometimes we also use the method of random search.
Random search, as the name implies, is the collision of experience and luck. We define a parameter range based on experience, then randomly select parameters within the range for testing and return the best result. For example, below, we define that parameter A varies in the range \([P1, P3]\) and parameter B varies in the range \([P4, P6]\).

The
RandomizedSearchCV
method provided by scikit-learn can also be used to
implement random search.
Exercise 21.3
Challenge: Learn and use
RandomizedSearchCV
to complete grid search parameter selection and finally
obtain the best result of 5-fold cross-validation.
Regulations: For the CART decision tree, search the
candidate parameter range
(2,
20)
for
min_samples_split
and the candidate parameter range
(1,
10)
for
min_samples_leaf, and randomly search for 10 groups of parameters. For
other parameters not specifically specified, use the
default values.
Read and learn by yourself: RandomizedSearchCV official documentation | RandomizedSearchCV official example
from scipy.stats import randint
from sklearn.model_selection import RandomizedSearchCV
## 代码开始 ### (≈3 行代码)
rs_model = None
## 代码结束 ###
Solution to Exercise 21.3
from scipy.stats import randint
from sklearn.model_selection import RandomizedSearchCV
### Code start ### (≈3 lines of code)
# Dictionary of parameters to be searched
tuned_parameters = {"min_samples_split": randint(2, 20),
"min_samples_leaf": randint(1, 10)}
# Random search model
rs_model = RandomizedSearchCV(model, tuned_parameters, n_iter=10, cv=5)
rs_model.fit(digits.data, digits.target)
### Code end ###
rs_model.best_score_ # 输出网格搜索交叉验证最佳结果
rs_model.best_estimator_ # 查看网格搜索最佳参数
Since the results of each random search are different, there is no expected output here.
You may find that the parameters determined by our grid search or random search are often not as good as the initial default parameters. In fact, scikit-learn has become very mature after years of development. Some of the default parameters are summarized by many people in daily use, so the default parameters often perform very well. Tuning parameters is important in machine learning modeling, but data and related preprocessing methods are often more important for the final performance of the model.