
1. Overview and Examples of Machine Learning#
Machine learning is a field of artificial intelligence that enables computer systems to learn and improve from experience without being explicitly programmed. It involves developing algorithms and statistical models that allow computers to perform specific tasks effectively without using rule-based programming.
Some common examples of machine learning applications include:
-
Image Recognition: Identifying objects, people, text, or other elements in digital images and videos.
-
Natural Language Processing: Understanding and generating human language, such as in chatbots, language translation, and text summarization.
-
Recommendation Systems: Suggesting products, content, or other items that a user might like based on their past preferences and behaviors.
-
Predictive Analytics: Forecasting future trends, behaviors, or outcomes based on historical data.
Machine learning models are trained on large datasets, allowing them to learn patterns and make predictions or decisions. The training process involves feeding the model with input data and the corresponding expected outputs, enabling it to adjust its internal parameters to minimize the difference between its predictions and the true outputs.
Once the model is trained, it can be used to make predictions or decisions on new, unseen data. Machine learning has a wide range of applications in various industries, from healthcare and finance to transportation and e-commerce.
1.1. Introduction#
Machine learning is an interdisciplinary field composed of probability theory, statistics, computational theory, optimization methods, and computer science. Its main research focus is on how to learn from experience and improve the performance of specific algorithms. This experiment will introduce the concept of machine learning and its related sub-categories.
1.2. Key Points#
Introduction to Machine Learning
Introduction to Supervised Learning
Introduction to Unsupervised Learning
1.3. Introduction to Machine Learning#
Machine learning is a field of artificial intelligence that enables systems to learn and improve from experience without being explicitly programmed. It is a powerful tool that has revolutionized many industries, allowing computers to perform tasks that were previously only achievable by humans.
Machine learning algorithms use statistical techniques to enable machines to “learn” from data, identify patterns, and make decisions with minimal human intervention. These algorithms can be used for a wide range of applications, such as image recognition, natural language processing, predictive analytics, and more.
The key aspects of machine learning include:
-
Data Collection: Gathering relevant and high-quality data is crucial for effective machine learning.
-
Model Selection: Choosing the right machine learning algorithm or model for the task at hand.
-
Training: The process of feeding data into the algorithm to “train” the model.
-
Evaluation: Assessing the performance of the trained model on new, unseen data.
-
Deployment: Integrating the trained model into real-world applications.
Machine learning has numerous applications across various industries, from healthcare to finance, and its impact continues to grow as the technology advances. As a professional translator specializing in machine learning, I am well-versed in accurately translating technical content while preserving the original markdown formatting.
Machine Learning is a branch of artificial intelligence, the core of which is machine learning algorithms, and it improves its own performance by gaining experience from data. The birth of machine learning was very early, but with the rapid development of computer technology and related fields in recent years, machine learning has become popular again.
To understand what machine learning is, let’s start with the definition of machine learning. A classic definition comes from computer scientist Tom M. Mitchell, who published the book “Machine Learning” in 1997. The original text is as follows:
Note
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
对于某类任务 T 和性能度量 P ,如果一个计算机程序在 T 上以 P 衡量的性能随着经验 E 而自我完善,那么我们称这个计算机程序在从经验 E 学习。
You may feel that the definition above is too academic, and even after reading it multiple times, you may not have fully understood the meaning it intends to convey accurately. In simple terms, this sentence emphasizes “learning”, and the core meaning is: computer programs improve their performance through the accumulation of experience.
The core of a computer program is what we call “machine learning algorithms”, and machine learning algorithms are derived from fundamental mathematical theories and methods. With algorithms that can learn autonomously, programs can automatically analyze patterns from training data and use those patterns to make predictions on unknown data.
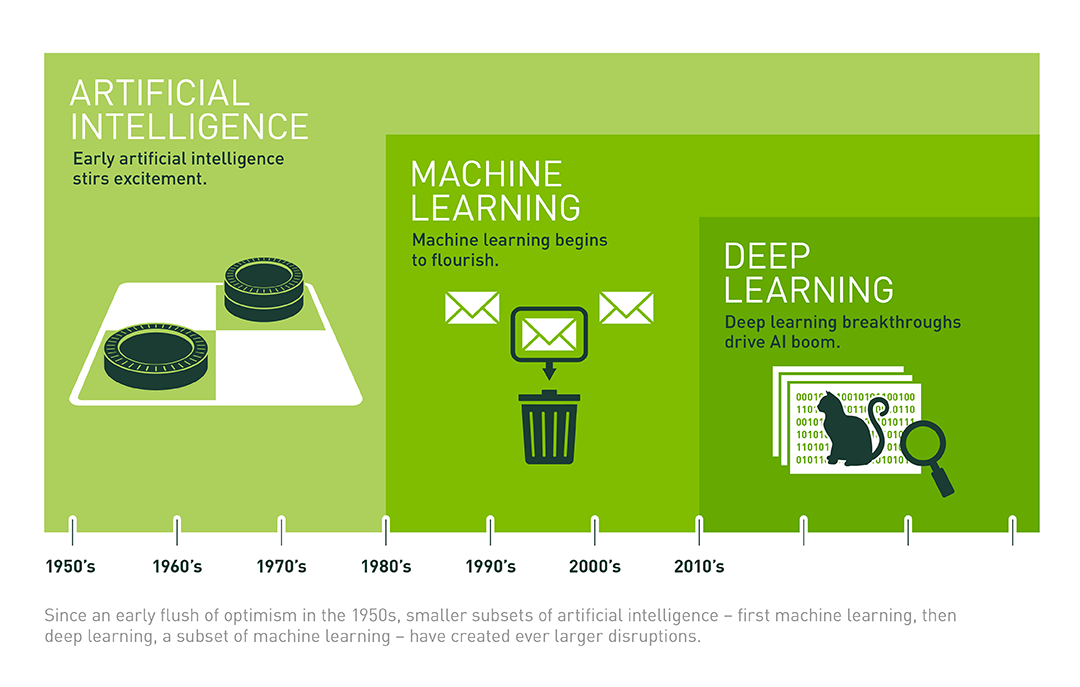
1.4. Machine Learning & Deep Learning & Artificial Intelligence#
We often see the three different terms of machine learning, deep learning, and artificial intelligence in media reports and academic materials, but it is often difficult to grasp the relationship between them. Are they inclusive, intersecting, or completely independent?
Here, we quote some of the views expressed in an article by veteran technology journalist Michael Copeland. Among the three, the concept that first appeared is artificial intelligence, which was proposed by John McCarthy in 1956. At the time, people were eager to design a “machine capable of performing tasks with human intelligence characteristics”.
Afterwards, researchers conceived the concept of machine learning, and the core of machine learning is to seek methods to achieve artificial intelligence. Thus, many machine learning methods such as naive Bayes, decision tree learning, and artificial neural networks (ANNs) emerged. Among them, artificial neural networks (ANNs) are an algorithm that simulates the biological structure of the brain.
Later on, deep learning emerged. The key to deep learning is to establish deep neural networks with more neurons and more layers. We have found that the learning effect of this kind of deep neural network even surpasses that of humans in areas such as image recognition.
So, regarding the above 3 concepts, the following relationship diagram can be summarized. Among them, machine learning is a means to achieve artificial intelligence, while deep learning is just a specific method within machine learning.
Currently, the “machine learning” we usually refer to can be broadly divided into four main categories: Supervised Learning, Unsupervised Learning, Semi-supervised Learning, and Reinforcement Learning.
In this course, we will focus on learning methods related to supervised learning and unsupervised learning. Among them, supervised learning usually solves classification and regression problems, while unsupervised learning mainly solves clustering problems, which are further divided into dozens of different algorithms.
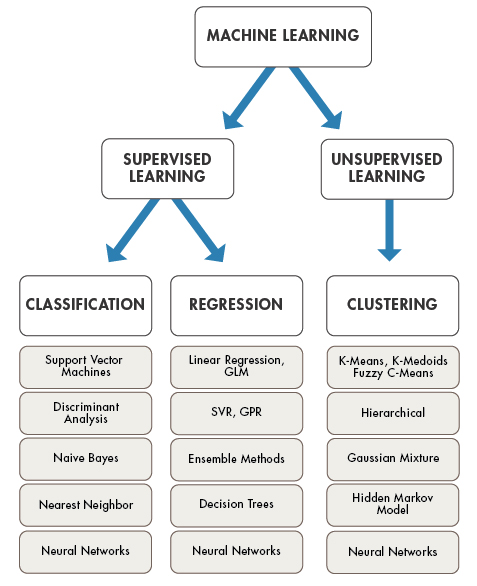
Next, we will focus on understanding the concepts of supervised learning and unsupervised learning, as well as what classification, regression, and clustering are all about.
1.5. Supervised Learning Methods#
Supervised learning is a machine learning approach where the algorithm is trained on labeled data, meaning the input data is paired with the correct output. The goal is for the algorithm to learn a function that maps the input to the output, so that when new, unseen data is provided, the algorithm can accurately predict the corresponding output.
Some common supervised learning algorithms include:
-
Linear Regression: Used for predicting continuous numerical outputs.
-
Logistic Regression: Used for predicting categorical outputs.
-
Decision Trees: Recursive algorithms that learn to partition the input space to make predictions.
-
Support Vector Machines: Algorithms that find the optimal hyperplane to separate different classes of data.
-
k-Nearest Neighbors: Algorithms that make predictions based on the closest training examples.
Supervised learning is widely used in applications such as image classification, spam detection, stock prediction, and many more.
To understand supervised learning, we must first start with the definition.
About the definition of supervised learning, here is the description from the renowned machine learning expert Mehryar Mohri in his book Foundations of Machine Learning:
Note
Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples.
Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples.
Let me explain the key terms in this sentence. The example input and output data pairs are actually the training dataset, where the input refers to the feature variables in the training dataset, and the output refers to the labels. Establishing the mathematical function is actually training the machine learning prediction model. This sentence describes a typical machine learning process. The key to supervised learning is that the provided training dataset has labels.
1.6. Supervised Learning Examples#
To better understand the definition of supervised learning above, here is an example of classifying flower species.
As shown in the figure, the training dataset provides the petal length features of 3 different types of flowers (training set features), and we already know the categories A, B, and C of these 3 flowers (labels). Then, for an unknown flower, we can determine its category (test sample label) based on its petal length (test sample feature). In the figure below, it would be more appropriate to classify the unknown flower as type B.
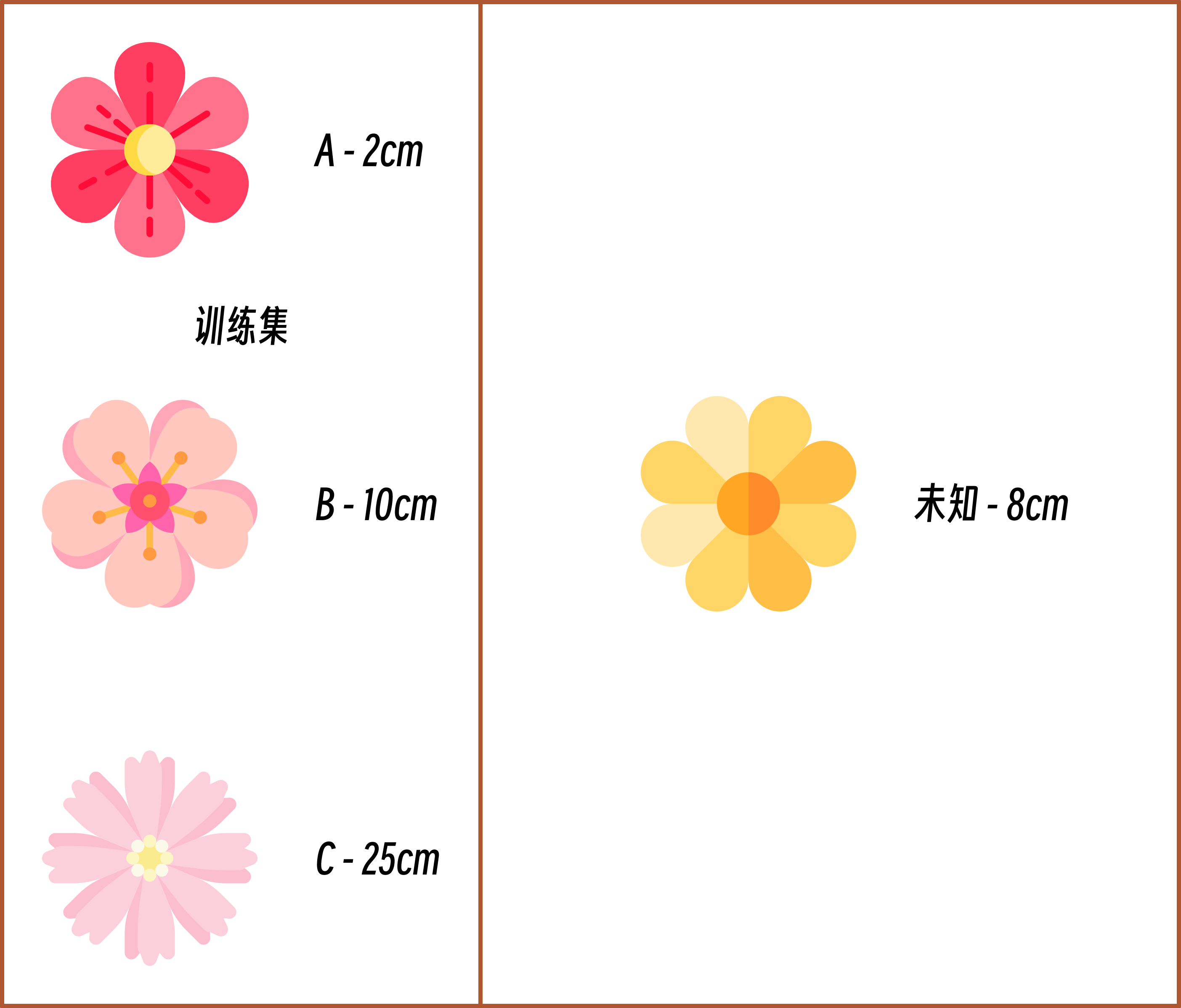
In summary, the “supervision” in supervised learning is reflected in the fact that the training set has “labels”. Just like the picture above, we provided known types of flowers, and for unknown types of flowers, we can compare the features and determine the type.
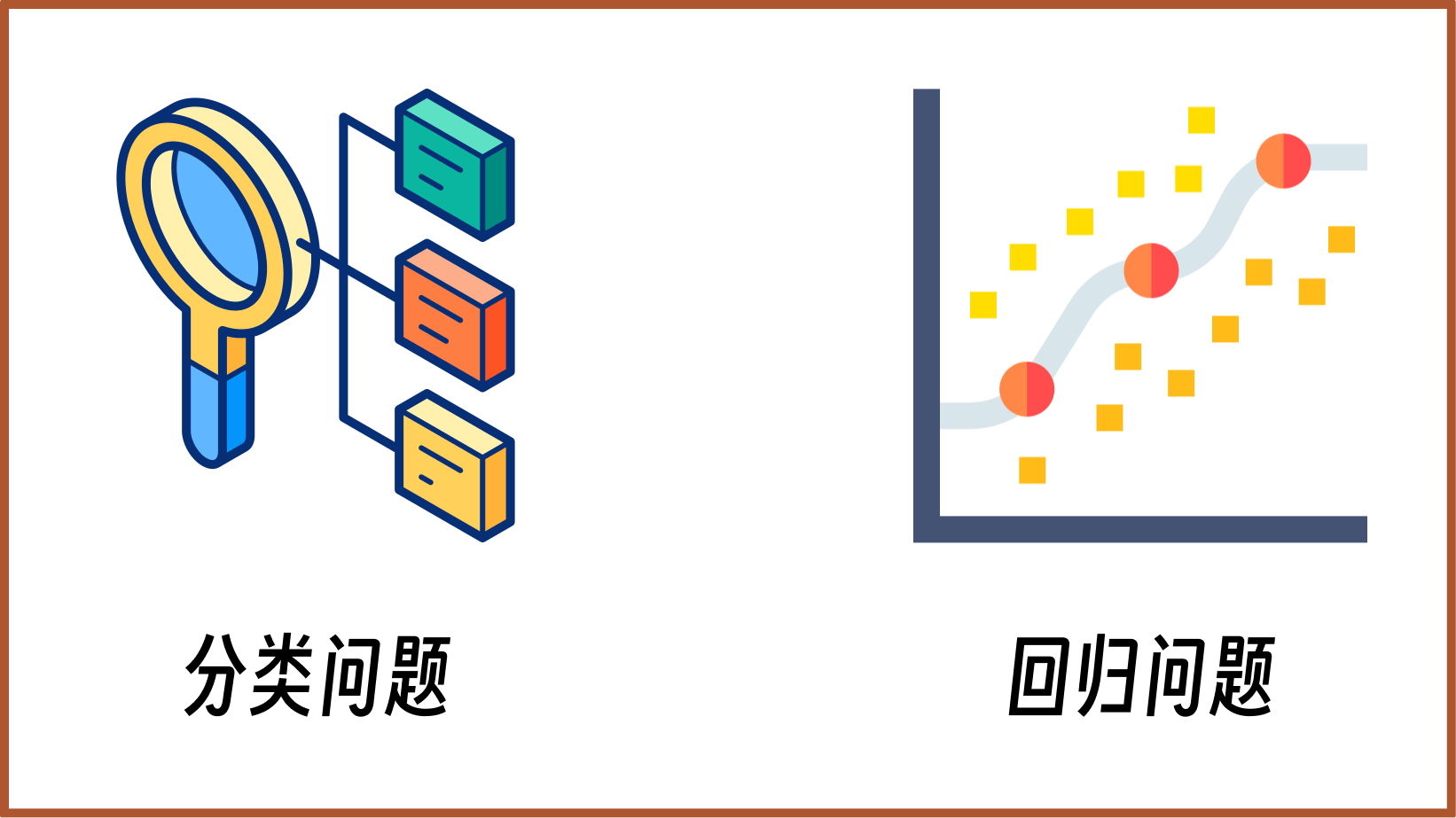
1.7. Classification and Regression#
Through the above small example, you should have a certain impression of “supervised learning”. And problems like the one above, where we recognize categories, are generally called classification problems in supervised learning. Classification is actually one of the most common problem types, such as: identifying the species of animals, identifying the species of plants, identifying the categories of various items, and so on.
Besides classification problems, there is another very important class in supervised learning, which is regression problems, and this is the content that needs to be learned in this chapter. First of all, like classification problems, regression problems have labeled training data, which is a characteristic of supervised learning. The difference is that classification problems predict categories, while regression problems predict continuous real values.
For example, stock price forecasting, house price forecasting, flood water level forecasting, these are all machine learning regression problems. Because the targets we need to predict are not categories, but real-valued.
1.8. Introduction to Unsupervised Learning#
Unsupervised learning is a type of machine learning where the algorithm is not provided with labeled data. Instead, it tries to find patterns and structure in the input data on its own. The goal is to discover hidden patterns or groupings within the data without any specific target variable to predict.
Some common unsupervised learning algorithms include:
-
Clustering: Grouping data points into clusters based on similarity. For example, grouping customers based on their buying habits.
-
Dimensionality Reduction: Reducing the number of features/dimensions in the data while preserving most of the important information. For example, extracting key features from images.
-
Association Rule Mining: Discovering interesting relationships and correlations between variables in large datasets. For example, finding products that are commonly purchased together.
Unsupervised learning is useful when you have unlabeled, unstructured data and want to explore and understand the underlying patterns. It can be used for tasks like customer segmentation, anomaly detection, and recommender systems.
In the introduction to supervised learning, we have quoted the statement of the famous machine learning expert Mehryar Mohri. He emphasized that when supervised learning algorithms accumulate experience from a dataset, a critical point is that the training dataset is labeled. To put it simply, labeled data means that I need to tell the algorithm that this is a house, this is a person, this is a flower, and then it will gradually learn to recognize these objects.
However, most of the data we encounter in life is unlabeled. Really, if you pay attention, you will find that unlabeled data is much more abundant than labeled data. Why is that?
Because adding labels to data is a very laborious task! The iris dataset and handwritten character dataset you use in supervised learning both require manual labeling. Just imagine the amount of work required to label tens of thousands or even millions of data points?
However, when faced with unlabeled data, we have another category of machine learning methods called unsupervised learning.
1.9. Unsupervised Learning Example#
In machine learning, unsupervised learning refers to the process of finding patterns and insights in data without any labeled or pre-defined target variables. Unlike supervised learning where the goal is to learn a mapping from input to output, unsupervised learning aims to discover the inherent structure or distribution in the input data.
Some common unsupervised learning techniques include:
-
Clustering: Grouping data points into clusters based on similarity. This can be used for customer segmentation, anomaly detection, etc.
-
Dimensionality Reduction: Reducing the number of features/dimensions in data while preserving the most important information. This can help with visualization and removing redundant/irrelevant features.
-
Association Rule Mining: Discovering interesting relationships and correlations between variables in large datasets. This is often used for market basket analysis and recommendation systems.
Unsupervised learning is a powerful tool for exploratory data analysis and can provide valuable insights that are not obvious from just looking at the raw data. It is an important part of the machine learning toolkit and is widely used in many real-world applications.
Unsupervised learning is a class of machine learning methods that is often used for data without labels, and one of the most common techniques used is data clustering.
Data clustering, in a visual introduction, is to divide a bunch of data into multiple subclasses according to the similarity of their features. For example, we have a flower dataset with two features: leaf length and width. We can visualize them in a two-dimensional plane based on these two features.

As shown in the figure above, you can clearly see that the entire data presents 2 different categories (clusters) with the naked eye. This also means that our dataset very likely contains features from 2 types of flowers. At this point, if you know which two types of flowers the features in the dataset are from, we can quickly complete the data labeling and label the entire dataset. That is, we can add labels to the unlabeled dataset through clustering.

Therefore, the “power” of unsupervised learning is very great. It can not only be used for data clustering, but can also help us add labels to datasets. As a result, many machine learning workflows actually become:
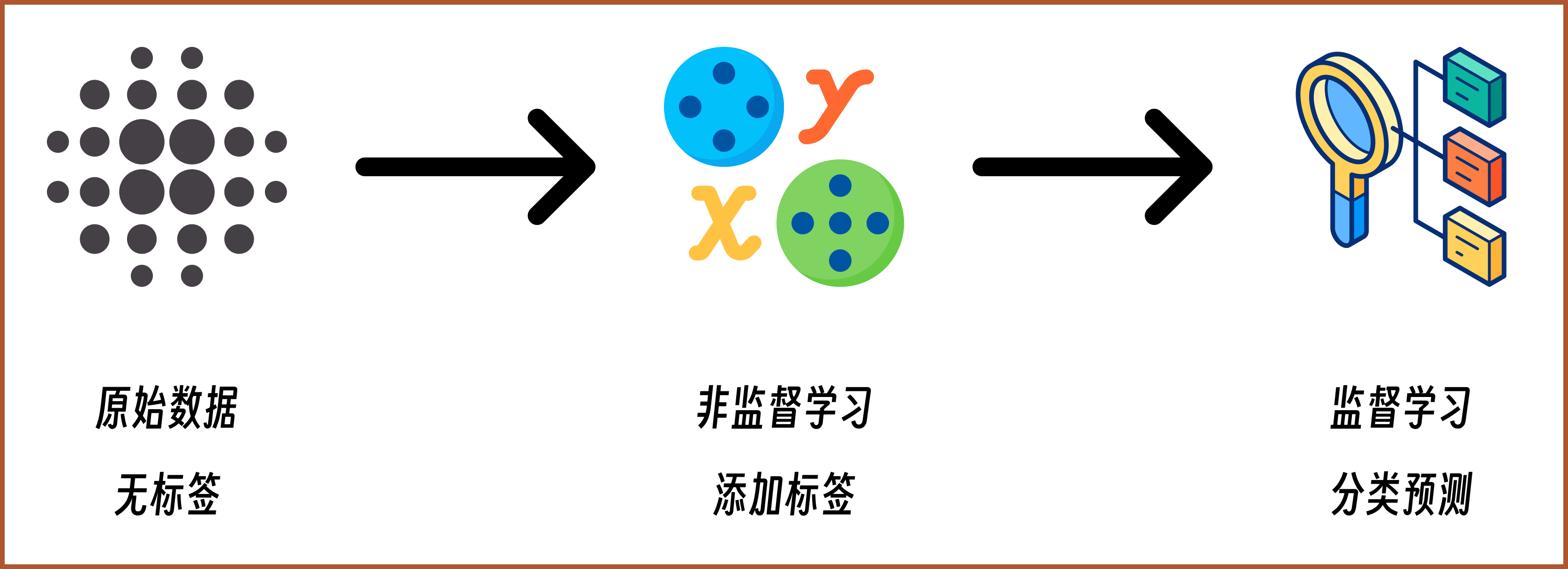
Of course, data clustering is just the main task in unsupervised learning. Unsupervised learning also actually includes data dimensionality reduction, graph analysis, association rule analysis, and other tasks.
1.10. Summary#
In this experiment, we focused on understanding the concepts of machine learning and its subcategories. You need to have a full understanding of supervised learning and unsupervised learning, and be aware of their essential differences. Furthermore, you should have an intuitive understanding and grasp of the characteristics and problems solved by regression problems, classification problems, and clustering problems.
Related links